
Self-Hosting DeepSeek-R1: A Journey into Local LLM Deployment
We don’t need to talk about the relevance of LLM’s as of writing this blog. In this blog we go through my journey in trying to get a little bit of that power into my own hands, run an LLM locally and test out its viability for my day to day use. Of course, we are slowly starting to see the incredible potential and also the many weaknesses of these models. Unless you are sitting on some incredible hardware, most of us have to with distilled models and those are even more limited in power. With all that said, it is still nice having your own hands. I have kept technical terminologies and assumptions of prerequisite knowledge to minimum in this post as the people interested in trying this out may not all be from a technical background. Some of you might find some of it redundant, and too light at some places, so I have provided links to documentation and other source material wherever needed so you can dive deeper into the tools and technologies. Here is the system I went with, more about it, later.
The Rise of Local LLMs
The ability to run powerful language models locally has transformed from a mere possibility to a practical reality. This transformation isn’t just about technical capability – it’s about control, privacy, and the democratization of AI technology. Obviously it is difficult to ignore Deepseek R1’s incredible performance but what caught the world by surprise is that it is completely open-source. That means that we don’t just get to try it out by downloading the weights but given enough knowledge of how to train LLM’s and capable hardware we could fine tune this to our specific tasks or even train a similar model from scratch.
Why DeepSeek-R1?
DeepSeek-R1 represents a fascinating development in the open-source AI community. As DeepSeek’s first-generation reasoning model, it brings something special to the table. Built on the foundations of Deepseek-V3-Base architectures, it promises performance comparable to OpenAI’s models while maintaining the flexibility of open-weights deployment. The smaller distilled models make use of Llama and Qwen architectures.
I do know that with time every new model will outperform its predecessors. We are still in the process of finding tests and metrics that are appropriate for testing the performance of these models in relevant ways. So, what did shake the world that was unique about Deepseek R1? We have been told by every leader in the LLM industry that one needs a warehouse full of GPUs to even attempt such a feat. Maybe we don’t require such crazy infrastructure to build our own LLM that is competent enough. Maybe people just love watching a good David and Goliath story unfold before them and people like me enjoy tinkering with any kind of open weight models. :) I strongly recommend anyone reading this to look into the architecture and training techniques used by Deepseek, this post is something I found really interesting: open-r1
This is only as of writing this post. When you may be reading this there might be other interesting models to look at that are open weights and can be accessed through something like Ollama. The choice of model also depends on use case and a lot of this information is available in the particular model’s documentation like what kind of data it was trained on and what kind of tasks it is good at.
Why Ollama?
Ollama is strong open source tool for locally hosting LLM’s. As of writing this I have seen people mainly use it for personal use (I may be wrong) but nonetheless it is a very powerful tool for trying out their many models readily available to be pulled for public use. All versions of Deepseek R1 are available from Ollama too. One can also pull a model and run it with their own choice configuration and make use of the many features of Ollama with new features added everyday. Being open-source it also allows developers to build their own plugins and related applications that run on top of Ollama to provide even more features. One such community integration tool is open-webui which I use to provide a feature rich frontend for my Ollama hosted models.
Setting Up Ollama
First, installing Ollama is remarkably simple. The project maintains excellent documentation and provides straightforward installation methods for various operating systems. As this blog revolves around Ollama I will provide the exact steps to install it. For the other tools and dependencies used you may have to look up their documentation. I will try to link those wherever possible.
- Depending on the type of OS you are running you will need to choose the appropriate method from the beginning of their documentation here: Ollama Docs
- Run the following to pull Deepseek R1 7B distilled version. You can look up the various models directly available here: https://ollama.com/search
ollama pull deepseek-r1:7b
- Run the model in your shell to verify.
ollama run deepseek-r1:7b
This is only the tip of the iceberg when it comes to customisations and accessibility provided by Ollama. Ollama uses a file named Modelfile to take in configurations that you can customise when running a model. You can modify context lengths and many other things here. Find the documentation to create Modelfiles here: https://github.com/ollama/ollama/blob/main/docs/modelfile.md. When Ollama is running it REST API endpoints like generate and chat that are accessible through port 11434 by default.
I used Open-WebUI to provide a frontend for my chat application. This was easier than building my own web application that would access my models through the REST API’s. But it would be unfair for me to say that Open-WebUI just provides a frontend for the model because you can do so much more with it like per chat model configuration, Retrieval Augmented Generation (RAG), user management and so much more. It is available as a docker container and a pip install depending on how you want to run it. You can get the installation instructions here, the tool is pretty much plug and play: Open-WebUI Docs
I strongly recommend you try this or other community driven tools that are mentioned in the Ollama docs. They provide a lot of value to whatever system you may be building.
Performance Considerations
Running DeepSeek-R1 locally requires careful consideration of hardware resources. In my experience, the model performs admirably on modern hardware, but there are several optimizations worth considering. Memory management is particularly crucial – the model’s memory footprint can be significant, but Ollama’s efficient handling helps manage this effectively.
This is the model I am running based on the capabilities of my system and the latency that I am okay with. A general rule is that you should have at least 8 GB of VRAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models. However, if you are okay with lower tokens/sec when the model overflows from the your GPU VRAM to RAM then you can look for models that only slightly go beyond your VRAM limitations and find the right balance. It is also important to note something else I have noticed, the initial model loading times are longer than when starting the model with the Terminal command.
Other things to consider are the overhead needed in terms of RAM and processing power for running Ollama and the other plugin tools with it, a lot of this may be trial and error until you find the system that provides a balance between the performance and features you want for your system. The memory usage of the system also depends on quantisation (4-bit, 8-bit, etc.) that is commonly used in models at the time of inference (just using the model in generate mode rather than training mode) and this can severely affect VRAM and RAM usage. Your system may also behave differently from mine when it comes to actually loading these models in runtime and having the rest of the system run alongside it.
Getting Ready for Internet Exposure
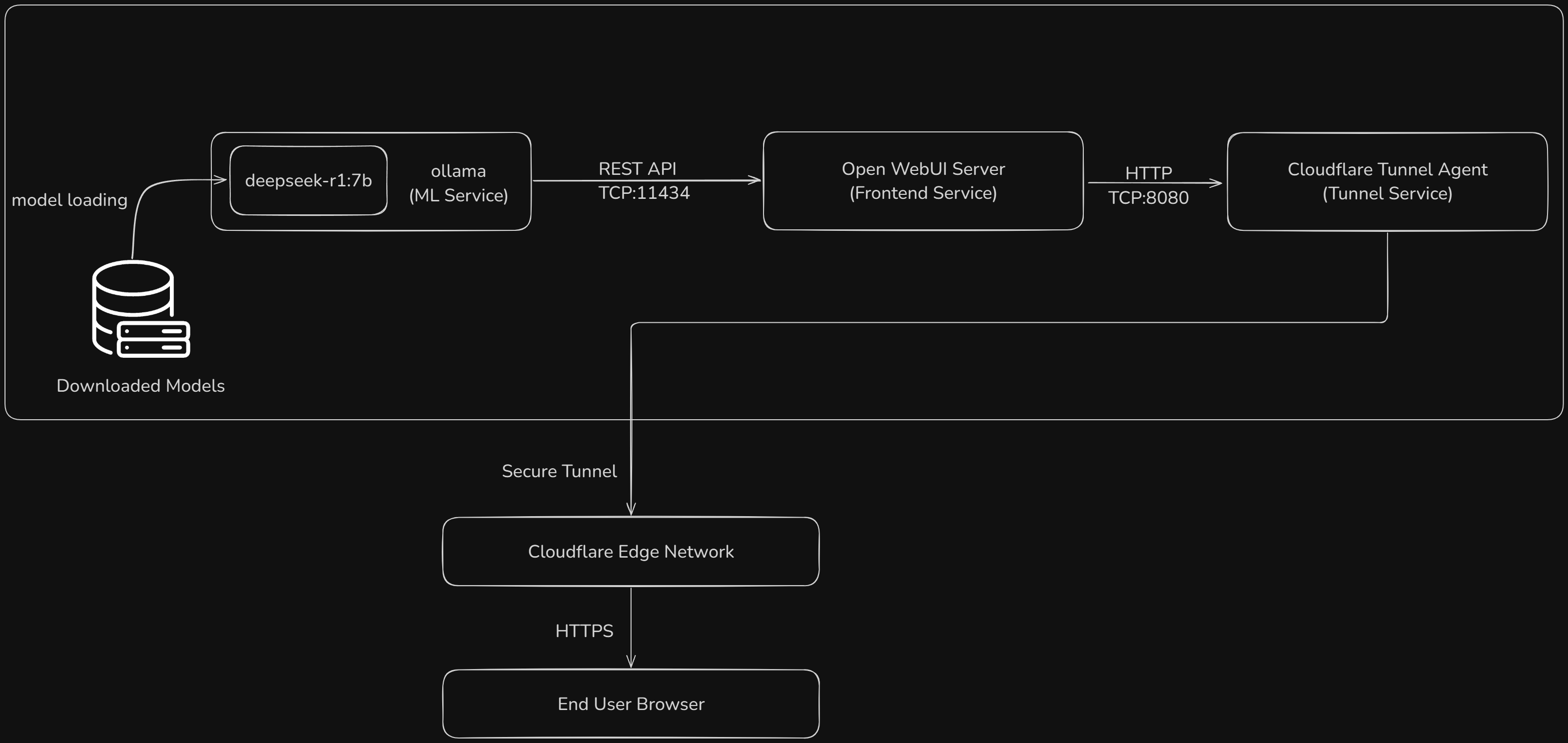
I think this is a good point for us to discuss the architecture of the complete system that I am using. These were the rough requirements I had for my system:
- All data should remain within my circle of devices. It need not be within my network alone. No second party should be receiving my data even as a middleware to provide any kind of service or anything of that sort.
- Model response (tokens/sec) should be around as fast as the reading speed of an average person.
- Model should be accessible from any device connected to the Internet given the appropriate login credentials.
Given these requirements, as seen before, I went with the following system architecture (there is no code involved, it is only a matter of proper setup):
We already have setup the system for us to access the model through the UI on the local system given a browser. What is left is to expose this system to devices outside my local network. There are several methods to achieve this. One can also expose the Ollama port directly and have a UI running elsewhere to access it. Regardless of what we want to expose there are several ways to do it*:
- Direct port forwarding: This is the most straight forward method to do it but one needs a static IP address to work with dynamic DNS. It also presents with security issues of directly exposing your service to the Internet without any safety measures.
- VPN Setup: This method provides a lot of control over who gets to access the service. It creates an encrypted network overlay. But all of this comes at a cost. It requires installation of VPN client on every client device (even mobile devices).
- Finally, the choice I went with, Cloudflare tunneling: It lets you not just expose a port to the Internet but rather create an encrypted tunnel between your service and Cloudflare’s edge network. If setup correctly, this will take care of most security concerns. It also allows for usage with dynamic IPs. The steps to do it are simple, go on to Cloudflare -> Sign up -> Dashboard -> Zero Trust -> Networks -> Tunnels -> Create Tunnel. Follow the on screen instructions to create your tunnel. You can get started on how to expose your local service using Cloudflare here: Cloudflare Zero Trust Docs It is important to note that these are just some of the common ways people choose to do it in, there are several more ways as there are when it comes to finding solutions in any comp science problem but this is what worked best for me.
There you have it, your own locally hosted LLM available to you from anywhere in the world. Try it out and let me know what you think, maybe you found a better way to do it, who knows. Either way I hope this post set you on the right path.
The Road Ahead
All of this was about taking control of something everybody uses on a daily basis and reducing dependency on external providers while keeping our data to ourselves. Having seen the rise of Deepseek data privacy becomes a bigger concern which is only truly solved when using the system within your local confine. It isn’t because I have anything against China, it is simply because the handling and usage of the data you send to these companies is subject to the laws of the country they operate out of. Most of us are not familiar of the data privacy laws anywhere other than the U.S. and possibly our home country if it is not the same. If your usage branches out of simply chatting with the LLM about basic topics it might know, such as building a system on top of it that allows for specific usage then make sure you understand how these LLMs work. With agentic systems being built for every use case and having systems not just call the model serially but also in a graph like manner (look into Langgraph if you are into that) it is essential for us to know how the models were trained and key aspects of the architecture of a modern LLM (transformers, attention mechanisms, etc.). This is important if we want to know what they are good at and what they are really bad at. I am a strong believer of the software 2.0 ideology popularised by Andrej Karpathy which suggests that ML is an important, yet not more than just a tool that will add to software systems of the future. Nonetheless I am eager to see how far these models can grow and what the state of ML is in a few years and if it can actually be more than just a tool, something humans can rely on to do things even they themselves can’t.
tl;dr you can use Ollama, Open WebUI and Cloudflared tunneling to host your own LLM on the Internet
I will update this post as and when I find any improvements or when I get access to better hardware do this not just as proof of concept but as a proper project
*Keep in mind that exposing your local system to the Internet in any way comes with its own risks if done improperly, please do this part only if you have some idea of what you are doing and it is all at your own risk. I do not recommend the use of any of these tools or methods without prior knowledge and I will not be responsible for any issues faced
*I am not in control of any of the software that is mentioned in this post, I am simply talking about tools that I tried and maybe they will help you too. I am not responsible for any damages or ill effects caused by careless download of software or model data and their effects.